
AIDSP-AI High Performance Data Service Platform
At present, AI/ML technology and applications (including LLM large models, general generative AI, etc.) have experienced rapid development and application. The demand for high-speed data access at the bottom layer in AI systems is becoming increasingly strong. Currently, there are various solutions in the industry, but there are some cost or performance challenges. There is an urgent need for a high-performance data service platform for AI&ML model training, model services, and other scenarios.
The data challenges and issues faced by AI/ML:
- GPU shortage: "Currently, GPUs are more difficult to obtain than drugs..." (Tesla Elon Musk); Even for large cloud providers, allocation takes 12 months or longer.
- Low GPU utilization: Even if a GPU is obtained, the GPU utilization is still very low (possibly due to data access issues); GPU spends time waiting for data loading/preheating, rather than computing.
- Expensive AI infrastructure: GPU resources and dedicated high-performance storage infrastructure are expensive, resulting in cost issues for large-scale AI/ML computing.
- Massive data processing/inefficient access: General artificial intelligence typically requires massive amounts of data to support, which also requires enterprises to effectively store, manage, and access large amounts of data with high performance.
- Long model training/online time: AI/ML data access/service performance slows down AI/ML model training and online time, affecting the ability of enterprises to quickly build and deploy models.
Storage/caching/data access systems required for AI/ML
- High performance parallel storage systems: GPFS/CPFS, Lustre, etc
Advantages: High performance, good POSIX compatibility Disadvantage: High cost; Poor scalability
- Distributed object storage systems: AWS S3, OSS, MinIO, etc
Advantages: Low cost and good scalability Disadvantages: Average performance; POSIX compatibility is limited
-Storage middleware: JuiceFS, JindoFS, etc
Advantages: Moderate cost and good performance Disadvantages: Private data format; High data governance/operation and maintenance costs
- AI data service platform/caching system: AIDSP
Advantages: Low cost, good performance, and simple data operation and maintenance Disadvantage: POSXI compatibility is limited
Selection criteria for data service system/cache system/storage system architecture required for AI/ML model training
- Overall cost:Build a high-performance data access platform for AI computing tasks at a lower cost - object storage+caching system
- Performance and Protocol Support:Provides high-performance data access interfaces, compatible with multiple data access protocols (POSIX, S3, HDFS, etc.)
- Open data format and architecture:Supports transparent data formats (keeping the original storage directory and file format unchanged); No vendor/technology lock in
- Data governance/operations:Reduce the impact of data governance/operations on training processes/efficiency (minimize data migration time, simplify Data Loader, Data Pipeline processes, reduce operations, etc.)
-

System architecture and main technical features
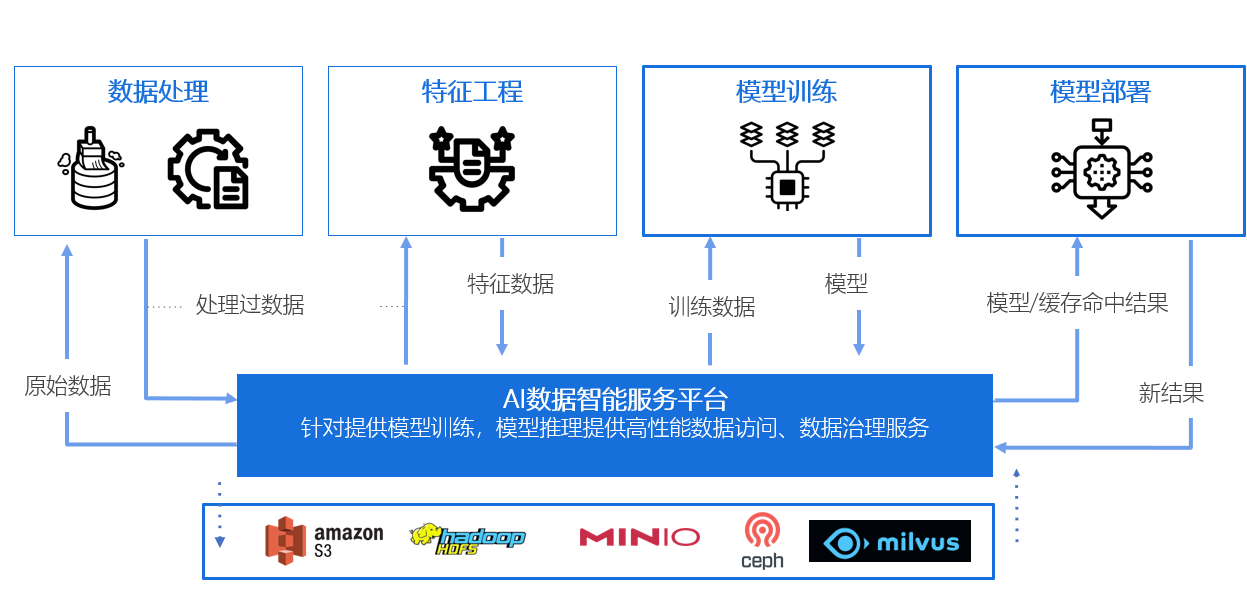
AIDSP provides high-performance data access for AI/ML computing such as Large Language Modeling (LLM), Large Scale Natural Language Processing (NLP), and Computer Vision (CV), covering the entire lifecycle of AI computing from data processing, feature engineering, model training, and model deployment. It provides functions such as multi-source heterogeneous data connection, high-performance data caching services, data interface conversion, and data directory management.
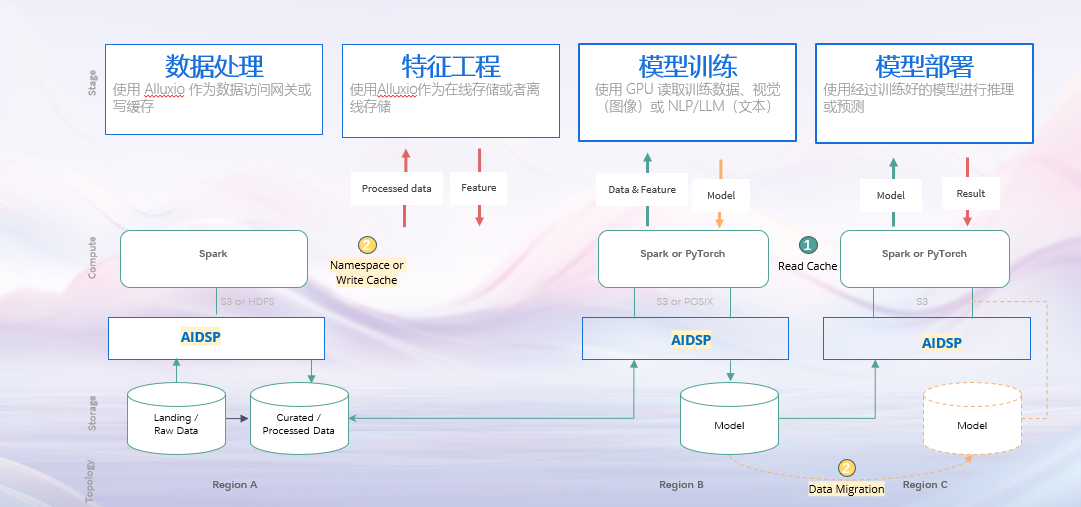
Unified namespace capability:Cross cluster, cross cloud, providing unified storage abstraction
- Reduce the implementation cost of data access technology across clusters and data centers.
- provides a foundation for the ability of global data circulation, integration, and management.
Unified data access/orchestration capability: Unified data access portal, blocking the potential impact of storage technology selection on upper level computing and applications.
- Reduce the cost of adapting new computing/applications to multiple storage systems; Reduce the transformation cost of upper level computing/applications during storage system migration, upgrades, and changes.
- Overall improvement of adaptability to new computing and storage technologies.
Unified distributed cache acceleration capability:Improve data access IO performance and reduce cross domain network overhead
- Improve the performance of computing and applications, and enhance the efficiency of computing resource utilization.
- Reduce cross domain network overhead costs, especially in situations where bandwidth resources are tight and costs are high.
Unified strategic data management capability:A new technical solution for data cold and hot backup is provided by implementing cold and hot hierarchical storage of data without affecting the calculation and application of upper level data.System technical architecture and main functions
The main core functions provided by the AI high-performance data service platform include the following:
1. Unified Namespace
Storage and computing are generally the two largest blocks in the entire AI data architecture. There are many storage options available now, with traditional HDFS in big data, and more and more cloud native applications using object storage, such as AWS clusters, MINIO clusters, cloud based S3 object storage, and so on. Originally, there may be inconsistencies in the interfaces between these object stores. Hadoop is an HDFS interface, while object storage is generally based on the S3 standard. Previously, cross storage computing required different interface adaptations, and many times users needed to provide a unified virtual storage layer and a unified data access interface. AIDSP can serve as a unified storage gateway, connecting local MINIO clusters, HDFS clusters, and cloud based S3 clusters. On top of these, it can provide HDFS interfaces, S3 interfaces, and even Posix interfaces. For both the big data Spark computing engine and the Python machine learning engine at the upper level, unified data access can be provided, which is equivalent to implementing a virtual storage gateway. It not only adapts the storage interface, but also provides caching services to bring data closer to computation and improve computing performance. AIDSP can integrate the underlying storage system and unify the namespace, which can draw inspiration from the implementation principle of the Linux file system's mount function. The following is the basic idea for implementing this function with AIDSP: Definition of Mount Point: Similar to the mount command in Linux file systems, AIDSP needs to define a mount point to specify the path of the underlying storage system. Each underlying storage system has a corresponding mount point, which represents the entry point to access the underlying storage system in AIDSP.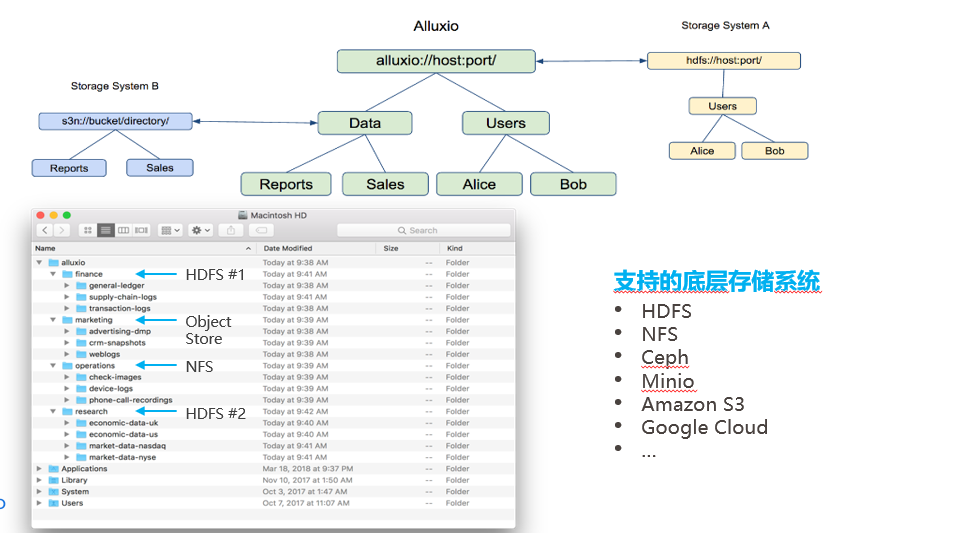
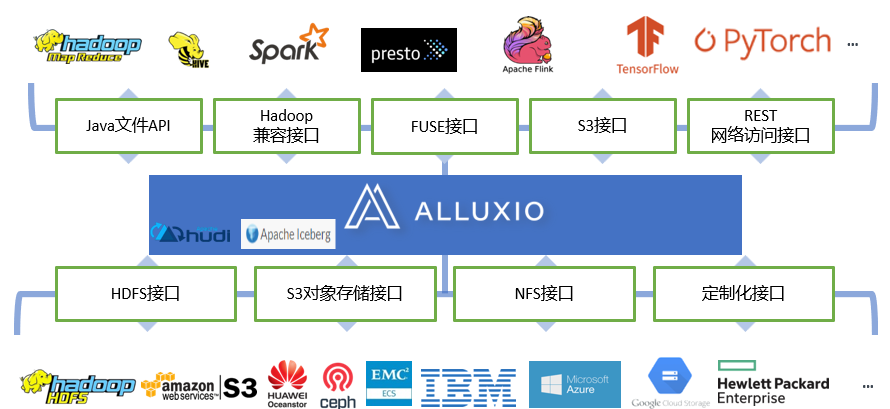
2. Unified Data Access
The unified namespace feature of AIDSP provides the ability for interface conversion, allowing users to access data on the underlying storage system through a unified access interface. Through this feature, users can access data through interfaces that are not directly supported by the underlying storage system. Specifically, AIDSP acts as an intermediate layer between the user and the underlying storage system. Users interact with AIDSP and access data using the unified interface provided by AIDSP. When a user initiates a data access request, AIDSP will parse the request and convert it into the original interface supported by the underlying storage system based on internal mapping relationships. The process of interface conversion is transparent and imperceptible to users. Users can use a unified interface to read, write, delete, and other data operations without worrying about the specific interfaces supported by the underlying storage system. AIDSP is responsible for converting user requests into operations that can be understood and processed by the underlying storage system, thereby achieving data access.
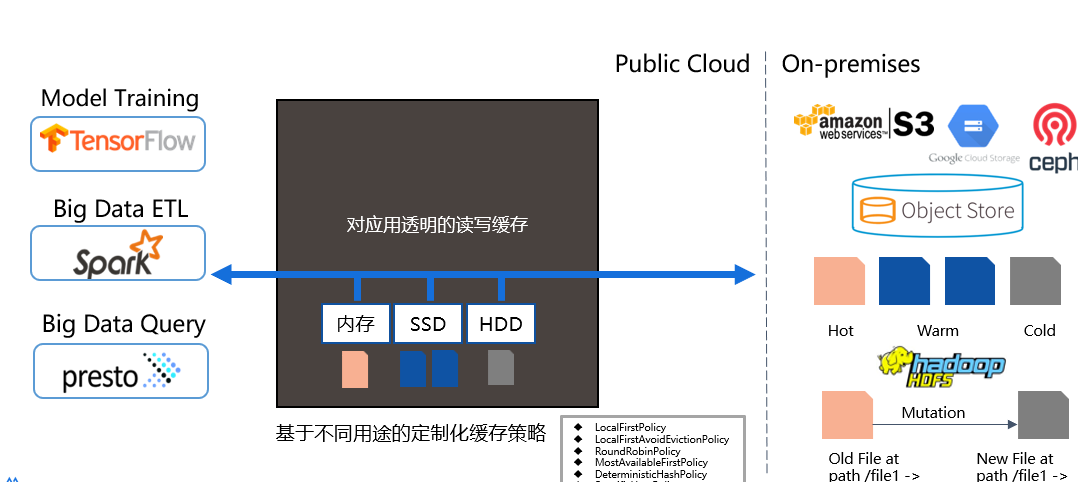
3.Hign Performance Data Caching Service
AIDSP provides highly unified distributed caching acceleration capability. By utilizing memory, SSD, and HDD for layered cache acceleration, a large amount of hot data can be placed on the data service platform to provide overall cache acceleration. As a distributed cache, AIDSP manages its local cache and serves as a fast data layer between user applications and various underlying storage, greatly improving I/O performance. AIDSP cache is mainly used for storing hot and transient data, rather than long-term persistent storage. The amount and type of storage that each AIDSP worker node needs to manage are determined by user configuration. Even if the data is not currently stored in AIDSP, files in UFS are still visible to AIDSP clients. When the AIDSP client attempts to read files that can only be obtained from UFS, the data will be copied to the AIDSP cache. AIDSP caching improves performance by storing data in the memory of computing nodes. In addition, data stored in AIDSP can be replicated to make "hot" data more easily parallelly used by I/O operations.
4.Strategic Data Management
AIDSP provides unified strategic data management capabilities, enabling transparent layering of hot and cold data. Users can define some data strategies, such as defining 7-day data as hot data, and the platform will automatically put this data into hot storage. After 7 days, the data will be automatically moved to cold data. When accessed, the data will be automatically transferred from cold data to hot data, achieving policy based transparent layering of cold and hot data.
Moving data from one storage system to another to achieve hot and cold layering while maintaining the correct operation of computing jobs is a common challenge faced by many AIDSP users. Traditionally, this is done by manually copying data to the destination, requiring each user of the data to update their applications and queries to use a new URI, wait for all updates to complete, and ultimately delete the original copy.
AIDSP can achieve more efficient cold and hot layering by using federated UFS to install multiple storage systems to a single installation point and providing policy based data migration capabilities between multiple UFS. For example, if a user wants to retrieve data from hdfs://hdfs_cluster/data/ Move to s3://user_bucket/, they can use AIDSP's union UFS to mount these two locations to/union/under the AIDSP path, and create a migration strategy to move data from HDFS to S3. AIDSP will execute policies and automatically move data, while users can continue to access their data using the same AIDSP path/union without worrying about their computing jobs failing after the data is moved. In the implementation of Union UFS in AIDSP, each underlying storage system is mounted as a sub UFS, and the path in AIDSP is mapped to one or more corresponding files in the mounted sub UFS. When a file is written to AIDSP, it can be configured to write to one or more sub UFS. When reading files from AIDSP, it can transparently read from any sub UFS mounted on Union UFS. This allows users to easily move data between storage systems while accessing data using a single AIDSP URI, regardless of which storage system the files are on.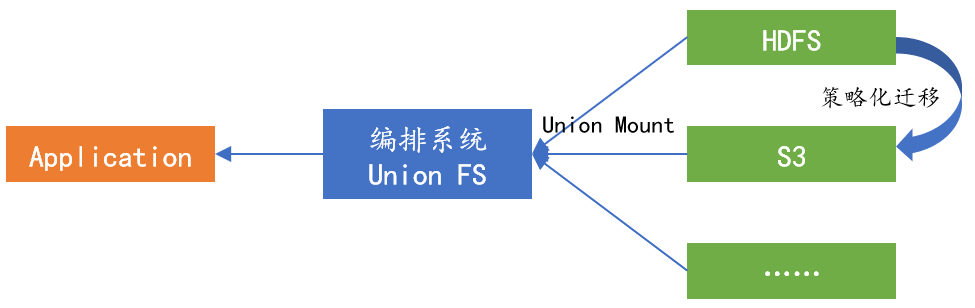
StarNET© Technology Co., Ltd
913, Building B, Ruichuang International Center, No. 8 Wangjing East Road, Beijing +86 10 68876296
info@starnet-data.comWebsite:www.starnet-data.com
WeChat No: starnet-2013