
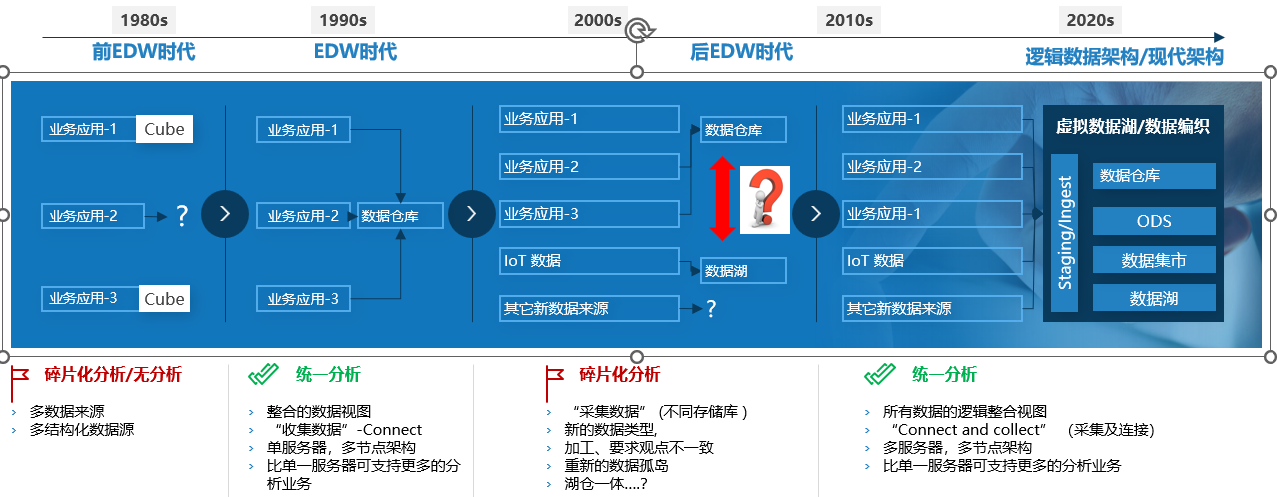
DVS-Data Virtualization System
Modern enterprises and organizations are continuously committed to integrating data as quickly as possible, with the aim of meeting the increasingly urgent data integration and acceleration needs of business stakeholders. Traditional data integration technologies deliver data in batches according to established plans and cannot support today's ever-changing data types, thus failing to fundamentally solve the problem. Data virtualization is a modern data integration method that has begun to address today's data integration challenges and lay the foundation for future data integration.
The main business scenarios and project construction requirements for enterprises to reflect the value of data:
Customer 360 view
Improve user experience (BI system, indicator platform, etc.)
Agile BI, independent data analysis by business personnel (BI system, flexible data retrieval platform, etc.)
IT infrastructure, data architecture upgrades (storage systems, database systems, big data systems, data silos, cloud data migration)
Efficiency improvement of data management and operation platform (data sovereignty/data autonomy, data asset management, data governance system)
Data security/data compliance/data auditing (data management/governance systems, etc.)
Challenges and considerations for building modern data architecture/management platforms for enterprises:
The construction cost is very high, and the input-output is relatively low
The difficulty of project development/deployment is high, and the construction cycle is long
Progressiveness product/technology? Lack of advanced data architecture and mature product support
Needs for localization, innovation, and independent innovation
Data Virtualization Technology
Without physically replicating data, connect data from different sources and types, create a logical view (data virtualization layer) with business semantics, and provide unified data access and interaction for various business systems and personnel.
Data Fabric
An advanced data architecture and management method that utilizes technologies such as data integration, data virtualization, enhanced data catalogs, active metadata, AI/ML, etc. to achieve unified data management, provide consistent data services, and support faster business decision-making innovation.
Data Management Platform/Big Data Platfomr/Data Lake
Manage and govern dispersed heterogeneous data elements in a physical replication/centralized manner, and serve various business departments and scenarios of the enterprise through the process of data collection, integration, governance, and analysis.
Data Platform/Business Platform
In the process of digital transformation of government and enterprises, the business and data precipitation of each business unit are carried out, and a data construction, management, and usage system including data technology, data governance, and data operation is constructed to achieve data empowerment; Unlike data management platforms, the data center emphasizes more comprehensive data integration, including various unstructured data sources.
Data Asset Management Platform
Enterprise level data asset management enables IT and business personnel to track and monitor data assets, providing quality data services for data analysis applications, including data asset search, metadata management, lineage analysis, and data asset sharing.
Data virtualization, as a data integration strategy, uses a completely different approach: it does not physically move data to a new consolidation location, but provides a real-time view of integrated data, while the source data remains in place.
Advanced data virtualization solutions will go further: establish an enterprise data access layer, providing universal access to all critical data sources of the organization. When accessing data, business users can query the data virtualization layer, which in turn retrieves data from the corresponding data source. The data access component is the responsibility of the data virtualization layer, so these users do not have to be constrained by the complexity of access, such as data storage location or data format. According to the implementation method of the data virtualization layer, business users only need to ask questions and obtain answers, and the underlying complexity can be handed over to the data virtualization layer for processing.
In most cases, these seamless "self-service" scenarios do not involve business users directly querying the data virtualization layer; On the contrary, it is most likely to interact with applications, web portals, or other user centered interfaces, and then obtain the required data from the data virtualization layer. The basic architecture is that the data virtualization layer is located in the middle, with all data sources and users (whether individuals or applications) at both ends, as shown in the following figure:
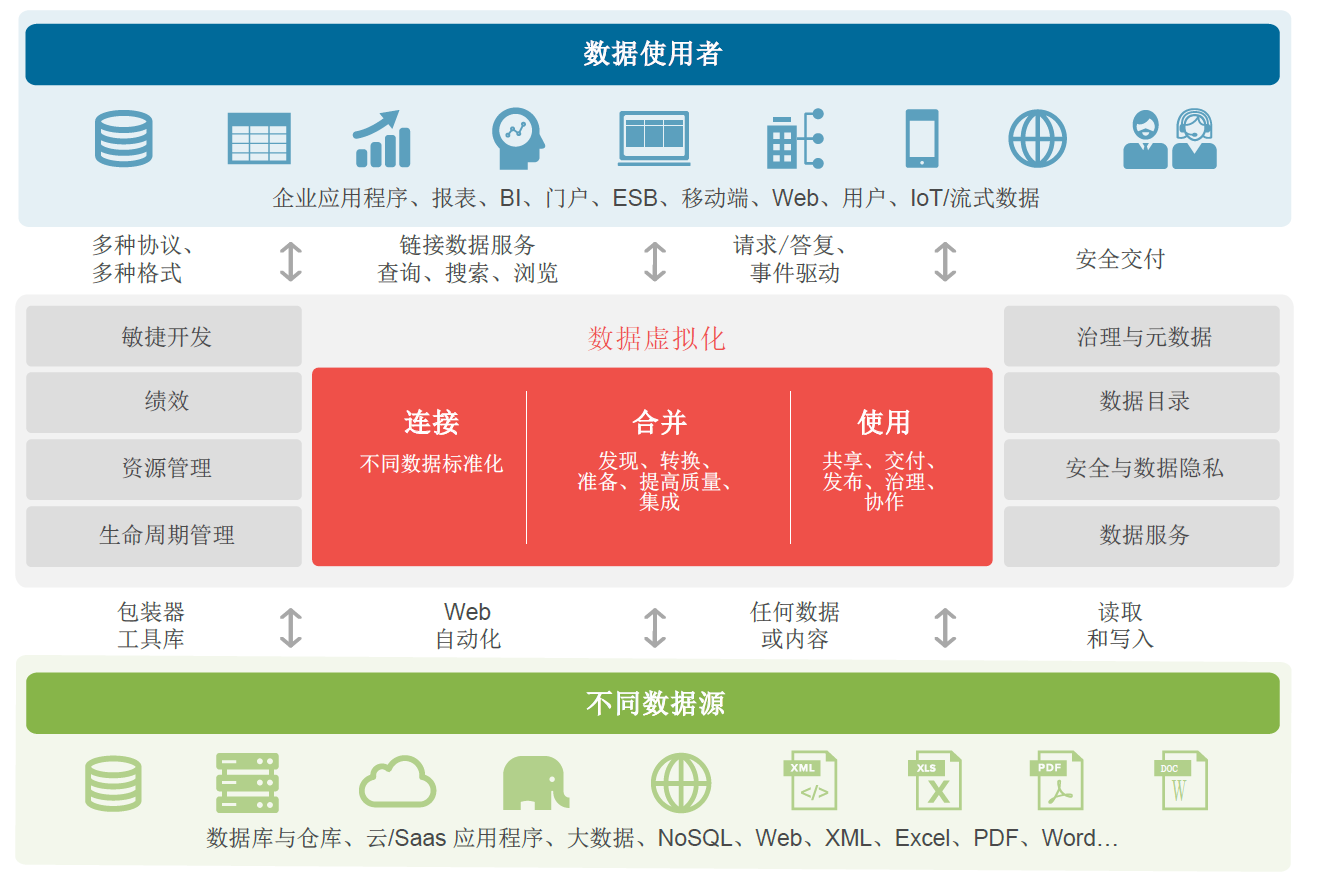
Due to data virtualization not replicating any data, the data virtualization layer itself does not contain any data. On the contrary, it only contains the metadata required to access various sources. The data virtualization layer is lightweight and easy to implement, and in addition, it has many advantages. For example, this architecture means that enterprise wide access control can be easily applied to the data virtualization layer, rather than being applied to each source system individually. It also provides a central location for developers to connect APIs, taking into account data sources with varying degrees of structure. Therefore, data virtualization is a modern data integration strategy. It is similar to traditional data integration solutions in terms of conversion and quality control functions, but can provide real-time data integration at lower costs, with faster speed and higher agility. It can replace traditional data integration processes and their associated data marts and data warehouses, and can also be simply reinforced to expand functionality.
As an abstraction layer and data service layer, data virtualization can easily navigate raw and derived data sources, ETL processes, enterprise service buses (ESBs), and other middleware, applications, and devices (whether deployed locally or based on the cloud), providing flexibility between business technology and information layers.
Data virtualization also has a disadvantage: unlike ETL processes, it cannot support the large-scale or batch data movement that some application scenarios may require.
Technical architecture and main functions
The main functions of a data virtualization system include the following:
1. Data blending function: Usually included in business intelligence (BI) tools. Data mixing can combine multiple sources to provide data to BI tools, but the permission to use the output content is limited to the tool and cannot be accessed by any other external application.
2. Data service module: Usually provided by data integration suites or data warehouse vendors, additional fees are required. These modules provide powerful data modeling and transformation capabilities, but their query optimization, caching, virtual security layer, support for unstructured sources, and overall performance are often weak. The reason is that these modules are typically designed as prototype ETL processes or Master Data Management (MDM) tools.
3. "SQL Like" products: This emerging category is particularly common among big data and Hadoop suppliers. These products can virtualize underlying big data technologies, enabling them to be combined with relational data sources and flat files for querying using standard SQL. This can be useful in the big data stack, but it can only stop here.
4. Cloud data services: Usually deployed in the cloud and with pre packaged integration with a few desktop and local deployment tools such as SaaS and cloud applications, cloud databases, and Microsoft Excel. However, unlike true data virtualization products, these products have a layered view and can delegate query execution, and can publicly standardize APIs across cloud sources for easy data exchange in medium-sized projects. Projects involving big data analysis, large enterprise systems, mainframes, large databases, flat files, and unstructured data are not within the scope of such services.
5. Data virtualization platform:These platforms are built from scratch with the aim of providing data virtualization capabilities to enterprises in a many to many manner through a unified virtual data layer. The data virtualization platform is designed for agility and speed across various application scenarios (regardless of source and user), surpassing other middleware solutions and enabling collaboration with them.
The technical implementation architecture of the data virtualization platform is as follows:
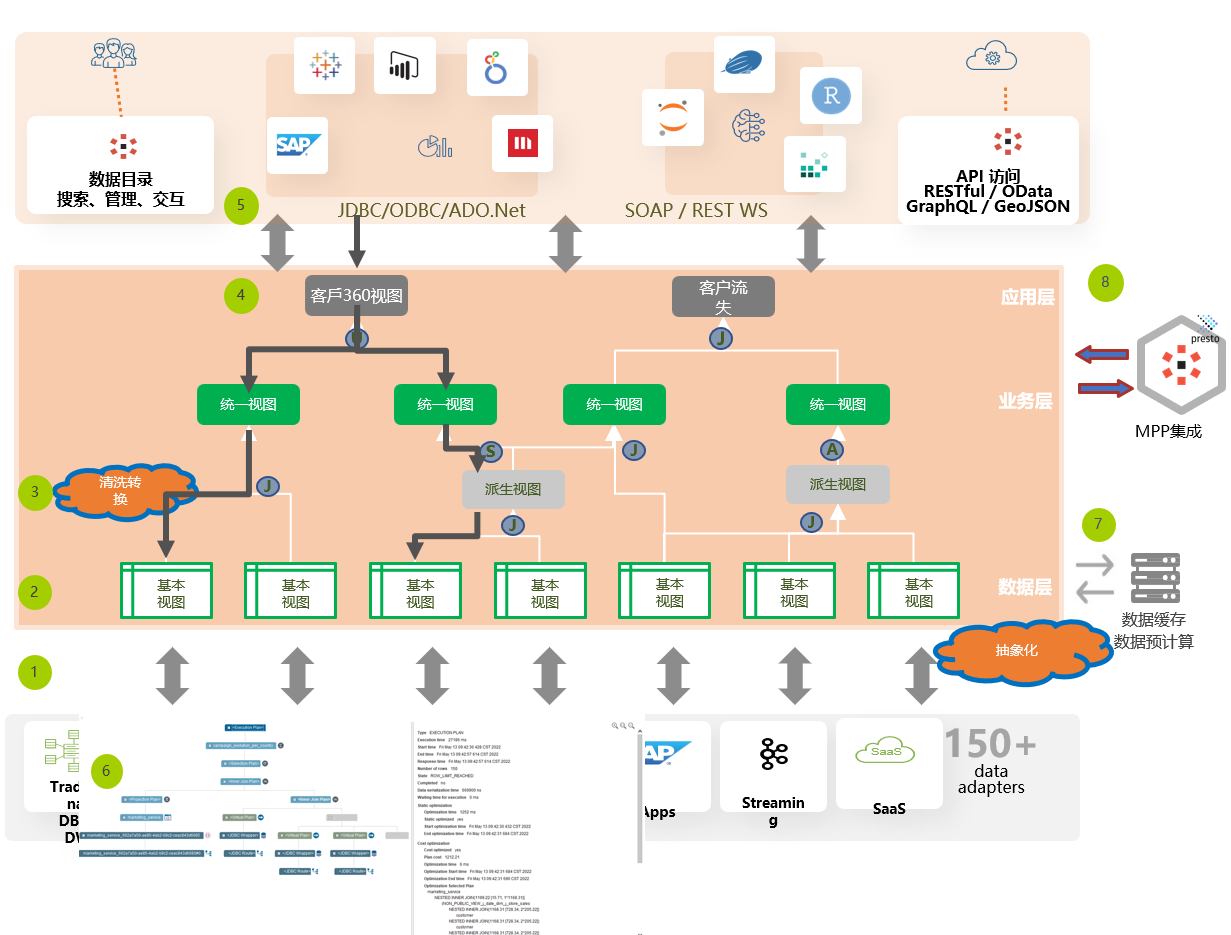
Data source connector: Firstly, establish connections with various data sources, which can include relational databases, data warehouses, cloud data storage, web services, APIs, etc. Through these connections, data from different data sources can be accessed and retrieved.
Metadata management:Metadata management collects and maintains information related to data sources, presenting data in a logical basic view (abstraction).
Virtual layer modeling (business layer): Establish a virtual layer to integrate and access data in SQL, allowing you to create user-friendly data structures without the need for actual data replication. The data model is created according to business requirements, so that users can access data in business terms and logical ways. This means that business users can use familiar business terminology to query and manipulate data without delving into the technical details of the underlying data sources.
Virtual layer modeling (application layer):It provides interfaces for different applications to access virtual data. These applications can include business intelligence tools, data warehouses, reporting and analysis tools, etc. The application layer allows different applications to access and utilize virtual data in a consistent manner, regardless of where these data sources are located.
Data access:The virtual layer modeling is completed, and users can access data through SQL or API, dynamically integrate and combine data from different data sources, enabling users to query and manipulate data in a consistent manner, regardless of the source of the data.
Performance optimization:The virtualization engine has performance optimization capabilities that can maximize query performance. It can automatically cache results and optimize query execution through intelligent query plans.
Data caching&precomputation: Create a cache layer to store copies of pre computed or queried data to improve query performance. Create summaries, reports, and summary data to easily understand the full picture of the data.
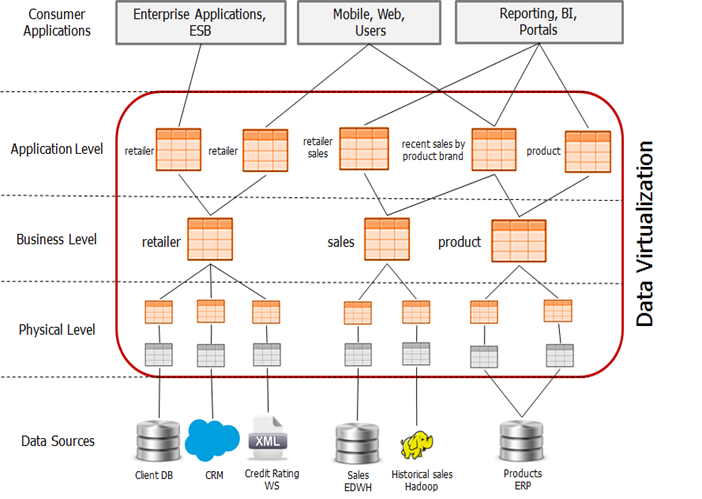
1. Data Modeling - Building Virtual Data Layers Across Multiple Data Sources
Connect various heterogeneous data sources of enterprises through data modeling tools, including structured data (relational databases such as Oracle, MySQL, PostgreSQL, etc.) and unstructured data, big data systems (Hadoop, Hive), file and cloud storage systems (HDFS, AWS S3, OSS, etc.). Build a derived view and a business view for business users based on the physical view of raw data. And complete the integration, processing, and logical modeling of various heterogeneous data during the virtual modeling process.
Implementing multi-source heterogeneous data connection based on Presto Connector
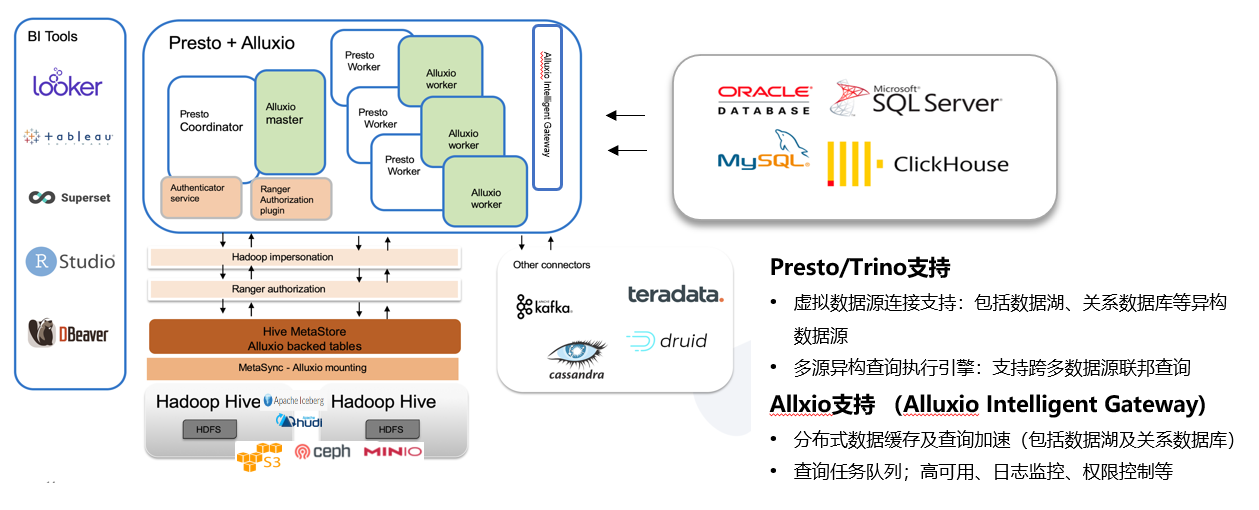
Presto/Trino supported data connectors
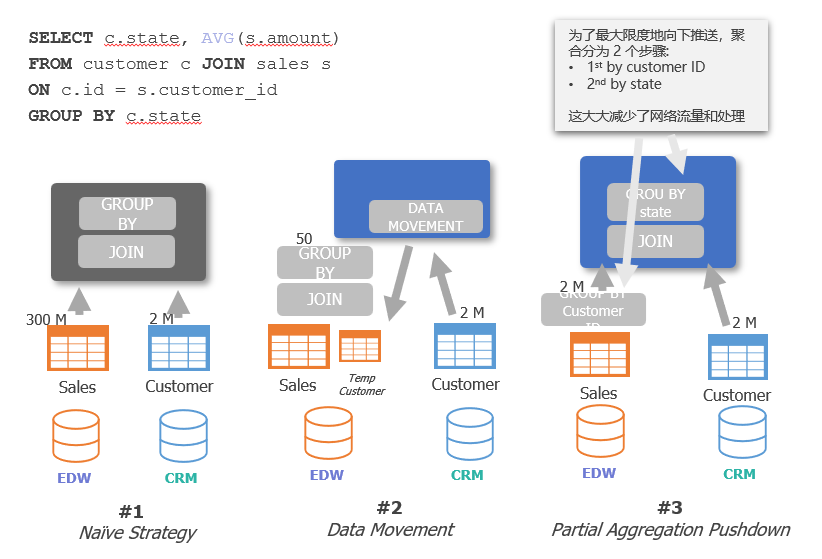
2. Federated Query Engine - Multi source Heterogeneous Data Query and Execution Optimization
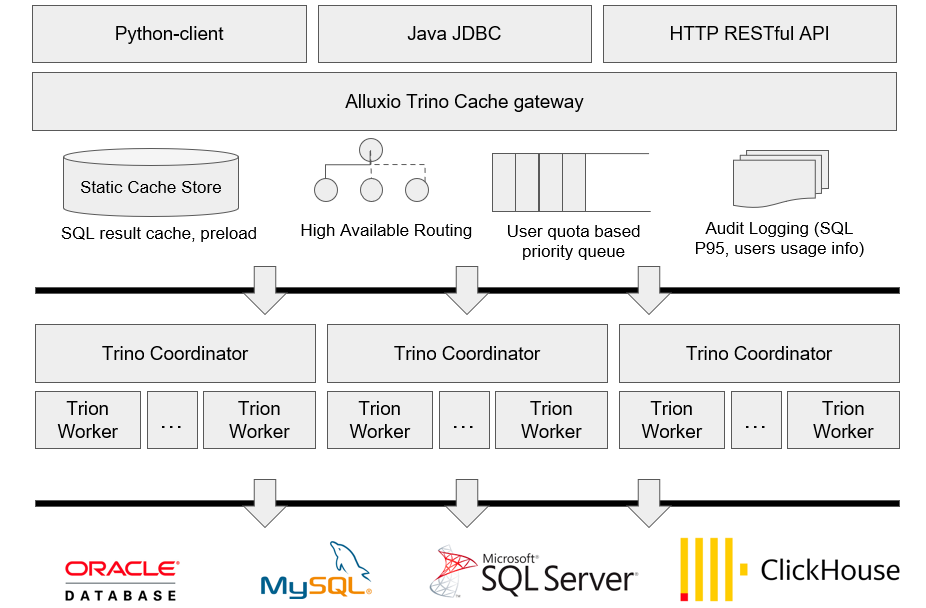
1)Presto Connector(Database Connector):Presto provides connector support for heterogeneous data sources such as Oracle, MySQL, SQL Server, and ClickHouse. It can connect different data sources through the JDBC interface by configuring the Catalog, and supports powerful cross source federated queries.
2)Presto Cluster(Coordinator + Worker): Split the Presto cluster into multiple Presto small clusters, each consisting of a single Presto coordinator and multiple Presto workers. Combining multiple small clusters with the Alluxio Presto Intelligent Gateway can achieve high availability and solve the inherent single point problem of the Presto Coordinator. At the same time, tasks can be divided into more fine-grained clusters through diversity clustering. For example, small tasks with frequent queries can be assigned to clusters with fewer nodes, while tasks such as ETL that require more resources can be assigned to clusters with more nodes and higher machine performance configurations.
3)Presto Intelligent Gateway: Gateway provides the following core capabilities through proxy Presto request:
- Caching of SQL results: In a multi-user scenario, the same BI report and ad hoc analysis of some SQL often require repeated queries. SQL result caching allows users to quickly obtain queried results, saving query time and resource costs. In the scenario of offline computing T+1 storage, it is possible to further cache and preload, enabling users to quickly obtain results when viewing reports.
- Presto cluster high availability: Based on the load situation of Presto small clusters, route query tasks to achieve load balancing between Presto small clusters. At the same time, when a Presto small cluster fails, new tasks can be routed to other Presto small clusters to avoid the unavailability of the entire Presto service, thus achieving the goal of high availability of Presto. As a stateless service component, Gateway's high availability can be achieved through Nginx composition.
- Priority queue based on user resource quota: When the Presto cluster has insufficient resources, submitting a large number of query tasks to the Presto cluster can easily cause task accumulation and lead to cluster crashes. According to actual needs, resource allocation is based on users, and Presto's traffic control is achieved through priority queues. At the same time, it can effectively monitor the usage of users at a certain moment, and manually adjust priority appropriately to make the operation and maintenance of the cluster more controllable.
- Audit log analysis: As a unified entry point for query tasks, Gateway can collect SQL requests from all users as audit logs. Based on this, it can further archive the status of SQL queries for subsequent analysis and optimization. For example, audit logs can be used to obtain indicators such as P99, P95, and P80 for daily SQL queries, in order to monitor the performance of the cluster and identify some hot or slow SQL for targeted optimization. For example, the user's usage period can be analyzed, and elastic scaling can be performed during idle time to allocate resources to other components, in order to achieve cost reduction and efficiency improvement.
4)In terms of front-end API access, the upper layer provides multiple calling interfaces:
- HTTP RESTful API: Allow users to submit SQL query tasks through HTTP requests, obtain SQL query progress, and obtain SQ query results.
- Java JDBC: Encapsulate the HTTP RESTful API to provide a convenient JDBC implementation for Java.
- Python Client: Encapsulation based on HTTP RESTful API, providing a client for Python.
3. Data Catalog - Self service Business Data Access Analysis
- Utilizing enterprise wide data models and metadata as the backbone of a self-service data strategy
- Autonomous data exploration and analysis similar to text search methods
- Enable business users to create their own queries and execute them from the directory using a drag and drop interface without the need to understand SQL
- Save the query as a favorite and export it as a new view, allowing other tools or users to reuse it.
- Place the dataset in context using descriptions, tags, lineages, endorsements, and usage activities (who accessed what, when, and how).
- This includes the expected execution time, the most commonly used queries on the dataset, and the most frequently used users and applications on the dataset.
- Suggested automatic dataset generated from activity metadata.
- Integrate directly with various BI tools and be able to export results in formats such as CSV and Excel.
StarNET© Technology Co., Ltd
913, Building B, Ruichuang International Center, No. 8 Wangjing East Road, Beijing +86 10 68876296
info@starnet-data.com
Website:www.starnet-data.com
WeChat No: starnet-2013