
1. Data Virtualization application scenarios
In the context of multiple data sources and formats, there are traditionally two ways for enterprises to integrate and consume data: one is for data developers to create a data processing program. Extract the data from the original data system, clean it up, store it in another database, and finally open it for business users to use.
Another approach is to export the data into an Excel file, which is then manually processed by business experts or IT personnel familiar with the data source, and then presented to business users for analysis. Both of these methods are very inefficient, not only in terms of time cost, but also require high skills from data preparation personnel. We can try using data virtualization platforms to better address these issues.
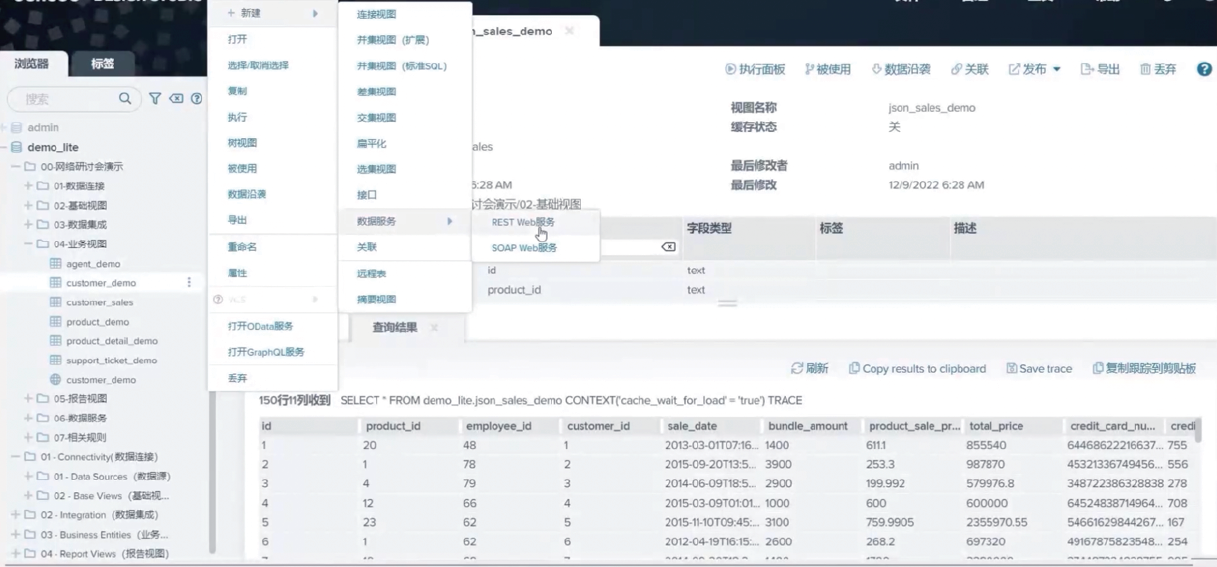
There will be three data connections in the example scenario: two parts of the data will come from the Web API (Json and Soap respectively), and the other part of the data will come from Oracle.
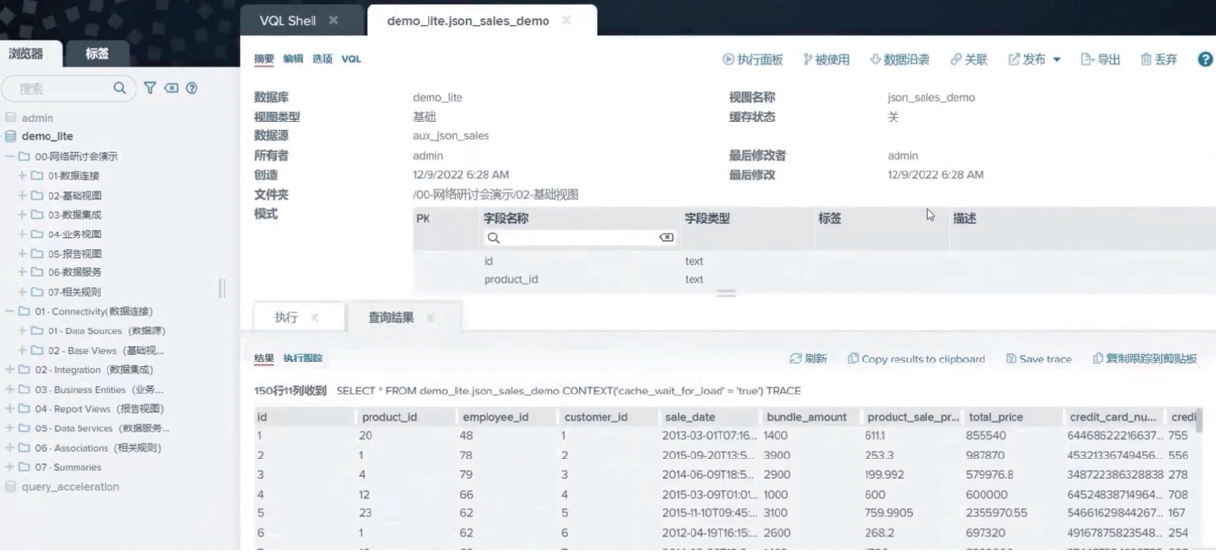
Step 1: Data connection
Step 2: Create a basic view to present the matching relationship between the data virtualization platform and the source data table
Step 3: Merge data tables and fields through data integration;
Step 4: Create a business view to facilitate business users to have a better understanding of data source information
Step 5: Build a report view model that associates multiple business views. The model can be output, saved, and easily modified
Build a logical report view using a data virtualization platform, and once completed, you can associate various BI tools for self analysis.
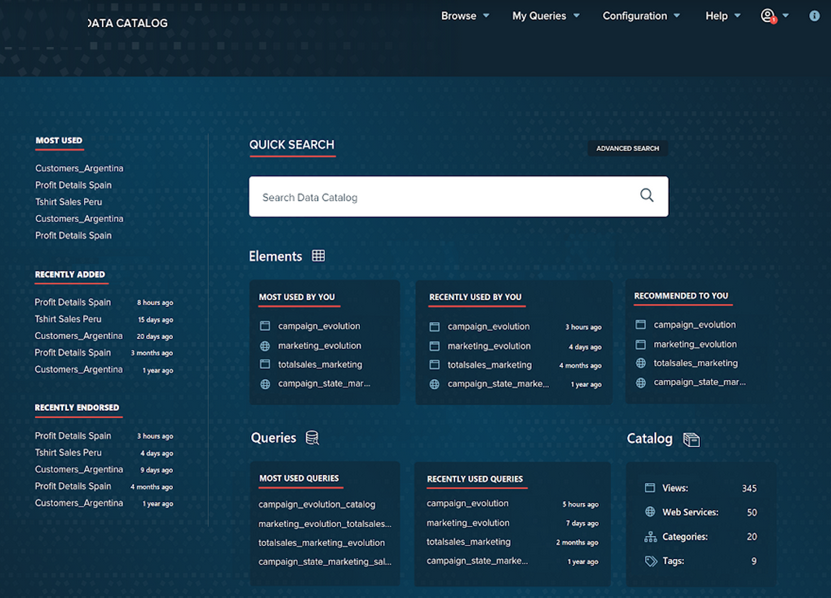
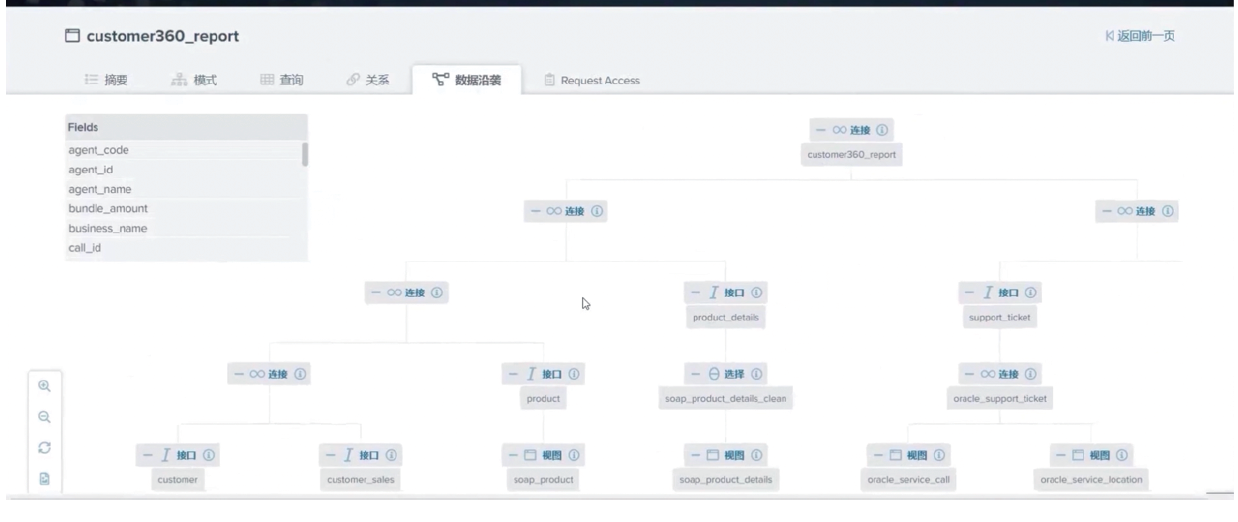
The common challenge for business personnel is that it is difficult to understand how much data assets a company has and which data assets can be used for data analysis and exploration. In response to this challenge, the data virtualization platform provides a data catalog tool. Users can actively read some information from metadata and build their data directory when building the entire metadata system. In addition, it also provides a search engine that can quickly help users find corresponding data assets, confirm whether they want them, and whether they are available.
Through this scenario, it can be found that: searching for the required data from the data directory, and then using BI tools to analyze the data, the entire process becomes very simple!
Data consumption is not only used for data analysis, but also has scenarios for sharing with third parties or business systems. For example, many enterprises with a data center often create many web APIs in the center to achieve data sharing, requiring a lot of code to be written, and the entire process is time-consuming and laborious. In fact, through data virtualization platforms, the APIs required for sharing data can be quickly implemented with simple click operations. For example, if you need to share information in the business view, simply create a new REST web service, set the data format, save it, and finally deploy this web API.
After deployment, users can directly access the shared data through this API. The entire sharing process is very convenient and efficient!
2. AI High Performance Data Service Platform application scenarios
1) Business Challenges
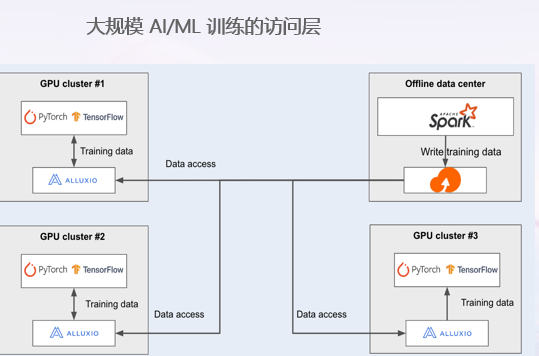
- Low GPU utilization: 20% -30% GPU utilization
- As the number of model training tasks increases, it becomes difficult to maintain data migration pipelines
- A large number of redundant replicas from the main data lake to AI/ML infrastructure platforms
2) Value Return
- Compared to cloud object storage, GPU utilization has increased from 20-30% to over 90%
- Reduce data engineering costs by 75%
- Only maintain active training datasets (less than 3% of the total dataset)
1) Business Challenges
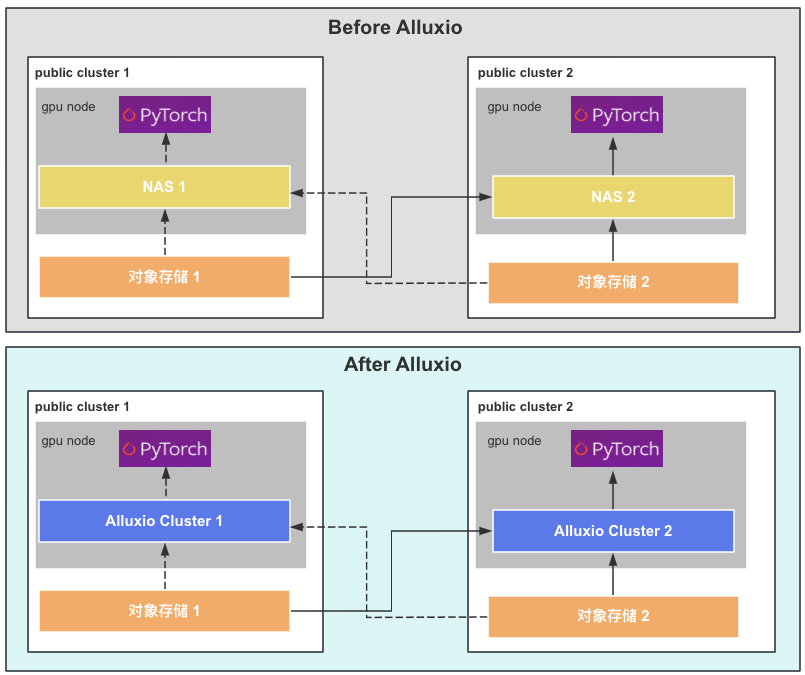
- The low efficiency of accessing training data in object storage leads to low GPU utilization
- The time and cost of copying data across clusters are high, resulting in a long training and deployment cycle for the overall model and high costs.
- Different departments downloading the same dataset to NAS results in a large amount of redundant data in the NAS, increasing storage and maintenance costs.
2) Value Return
- Throughput improvement: Compared to NAS and direct access to S3 storage, IO read speed increases by 5 times.
- Data download: Model training data preloading speed increased by 2 to 10 times.
- Training time: The model training time has been reduced from 18 hours to 14 hours (training script bottleneck).
-Simplified operation and maintenance: reduces a large amount of cross centralized data engineering operation and data redundancy.
1) Business Challenges
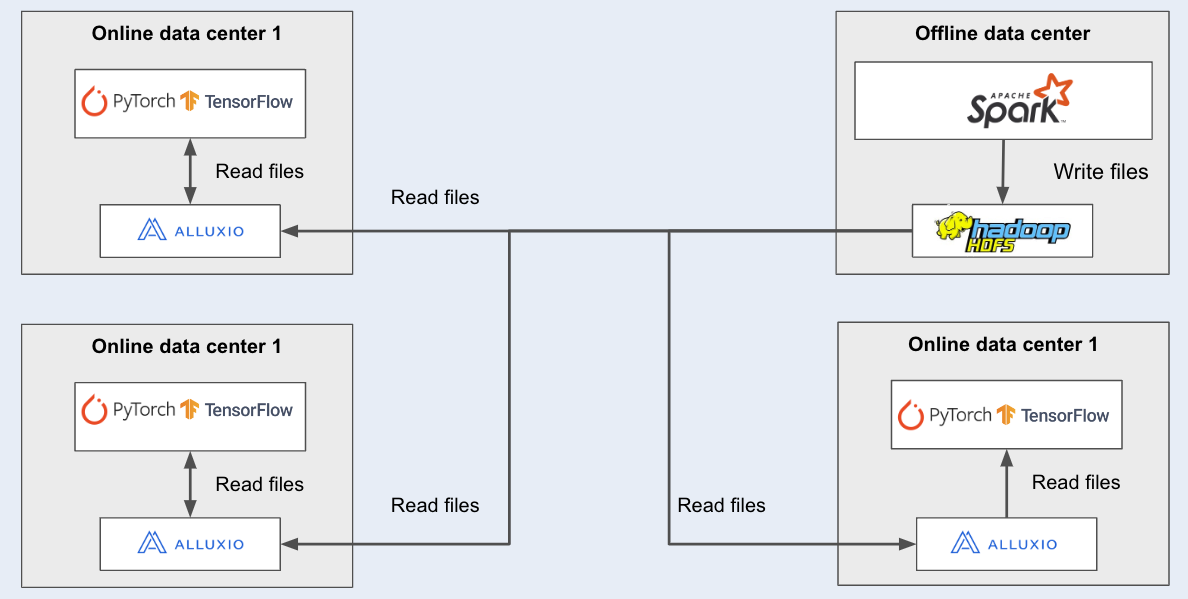
- The low efficiency of training data access in HDFS leads to low GPU utilization
- Network bottlenecks and high costs caused by cross data center/cross cloud data access
- Model launch/deployment costs are high and takes a long time
2) Value Return
- GPU utilization increased from 45% to 98%
- Improve user retention and viewing time on the platform
- Using AIDSP S3 API to increase model deployment speed by 5 times
- Reduce hardware costs by 50% through more efficient data access layers
Bringing a large language model from its initial training to deployment requires numerous systems and components. At Zhihu, we grappled with a multi-cloud, cross-region AI platform, requiring an efficient solution to facilitate the rapid training and delivery of models for production use cases. This led us to adopt the high-performance data access layer for LLM. This blog provides an in-depth look at Zhihu’s challenges, journey, and solution for LLM training and deployment. Through AI data service platform, we’ve significantly enhanced model training performance by 2 to 3 times and can deploy updated models every minute instead of hours or days. Also, our GPU utilization has doubled, infrastructure and operation costs have been halved, and we have established a resilient, efficient infrastructure capable of meeting our escalating AI demands. .
3. Telecom Applicaiton Scenarios
China Unicom's old Big Data architecture could not scale to process the amounts of data generated by the rapidly expanding number of mobile users. The complicated the architecture of its incumbent computing platform created a lot of new challenges to effectively use resources.To solve these problems, the company built a new software stack of Apache HDFS,Spark, Kafka and Alluxio. They used Alluxio as the core component for a unified, memory-centric distributed data processing platform with consolidated resources, and improved computation efficiency.
The real-time passenger flow analysis system for Hunan Mobile scenic spots is the first big data analysis system of Hunan Mobile that supports data volumes exceeding PB level. The system has implemented the Hunan Mobile Network Element Conversion System to convert and analyze real-time 5G data, enhancing the system's effective utilization efficiency of data. Realized multi scenario traffic prediction and monitoring, scientific planning, and precise personnel control. The total number of system connections has reached trillions, with a total of 13 billion records per day, with the largest single data reaching 10 billion records per day. The data processing capacity can reach up to 4.5TB/hour. Compared to the original business system, the data processing and computing speed has been improved by 9 times, and the average query performance has been improved by 150%. The support for online analysis has increased from tens to hundreds of users, greatly improving the efficiency of business analysis.
4. Energey Industry Solution
This project is the first big data standardization and governance platform project for domestic coal enterprises. The project has established an intelligent big data standard system and data standard specifications for Shaanxi Coal Industry by inventorying the existing big data assets of the enterprise. It has also implemented business functions such as data resource directory, data map, data lineage analysis, data security and privacy management, greatly improving the level of data intelligence for coal and charcoal enterprise.
This project is the first implementation case of StartNET data virtualization product in a large energy central enterprise in China. The project integrates all unstructured data (including big data systems and file systems) and structured data (various business systems based on Oracle and MySQL) of Huaneng Group, and provides a unified logical data service layer. The project comprehensively utilizes data encryption technology, data desensitization technology, and privacy computing technology to solve the long-standing problems of data security and data privacy protection faced by Huaneng Group in data sharing.
5. Government Industry Solution
The Shanghai Yangshan Port Automated Port Intelligent Dispatch Platform is the world's largest automated port intelligent dispatch platform. Through real-time processing of massive sensor data, real-time tracing of abnormal events in unmanned vehicles has been achieved, accelerating the localization of abnormal events, significantly improving operational efficiency, analyzing and optimizing specialized services in multiple ports. After the system was built, it improved the efficiency of port production organization and resource utilization, significantly reducing the queuing time of port trucks; The original scheduled operation of port equipment has been optimized to operate in real-time according to the optimal time and route, resulting in a 20 times increase in port operation efficiency compared to before.
This project is the built using hybrid big data architecture (Hadoop, Oracle database, graph database & knowledge graph). The primacy functionalities including data catalog, data map, Data lineage analysis, meta-data management, master data management, data quality management, data security and data privacy protection. It also using knowledge graph technology to support various business modeling and data discovery analysis.
6. Finanial Industry Solution
The project construction needs to connect with multiple technical teams (inconsistent storage and computing interfaces). 1) The computing side needs to quickly access a large number of small files on object storage. 2) It is expected to control the cost of using object storage
Key points of system architecture: 1) Data pulling from the cloud platform to the local computer room; 2) South facing OSS protocol access object storage; Northbound POSIX protocol provides data interface 3) Deploying Alluxio components in K8s environment
Business value embodiment: 1) Bridging storage and computing platforms from different vendors, reducing system integration costs for demand and suppliers; 2) Improving scanning speed by more than 10x through metadata caching; By using hot data caching to avoid duplicate pulling of OSS data, 3) Building intelligent cloud platform data infrastructure capabilities, providing users with heterogeneous storage integration and computing interface docking capabilities.

StarNET© Technology Co., Ltd
913, Building B, Ruichuang International Center, No. 8 Wangjing East Road, Beijing +86 10 68876296
info@starnet-data.com
Website:www.starnet-data.com
WeChat No: starnet-2013