
Hunan Mobile Scenic Area Real time Passenger Flow Analysis System
Mainly achieve real-time extraction of telecommunications related O domain business data (including CDR, signaling, SMS, etc.) collected by Hunan Mobile from the front-end system, load it into the backend big data analysis system after data preprocessing, and perform long-term storage and various business analysis on the data in the backend, including data query, advanced statistical analysis, warning analysis, trend analysis, graphical display combined with geographical location, and correlation analysis.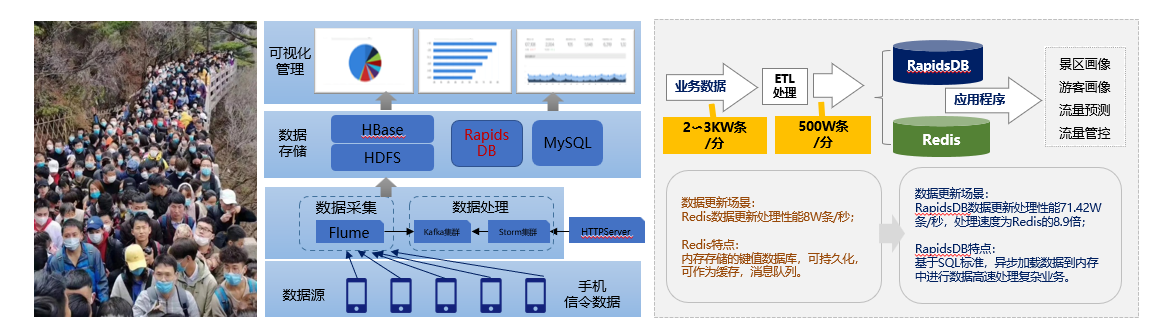
1. System Characteristics
- Platform framework:A big data processing platform based on leading distributed architecture (using technologies such as Oracle, Hadoop/Spark, Solr, Impala, Big Data SQL, etc.); At present, the scale of distributed cluster nodes has reached over 100 servers, with a total computing power of 1600 cores and a total storage capacity of over 6PB. The cluster size can be expanded online according to future business growth.
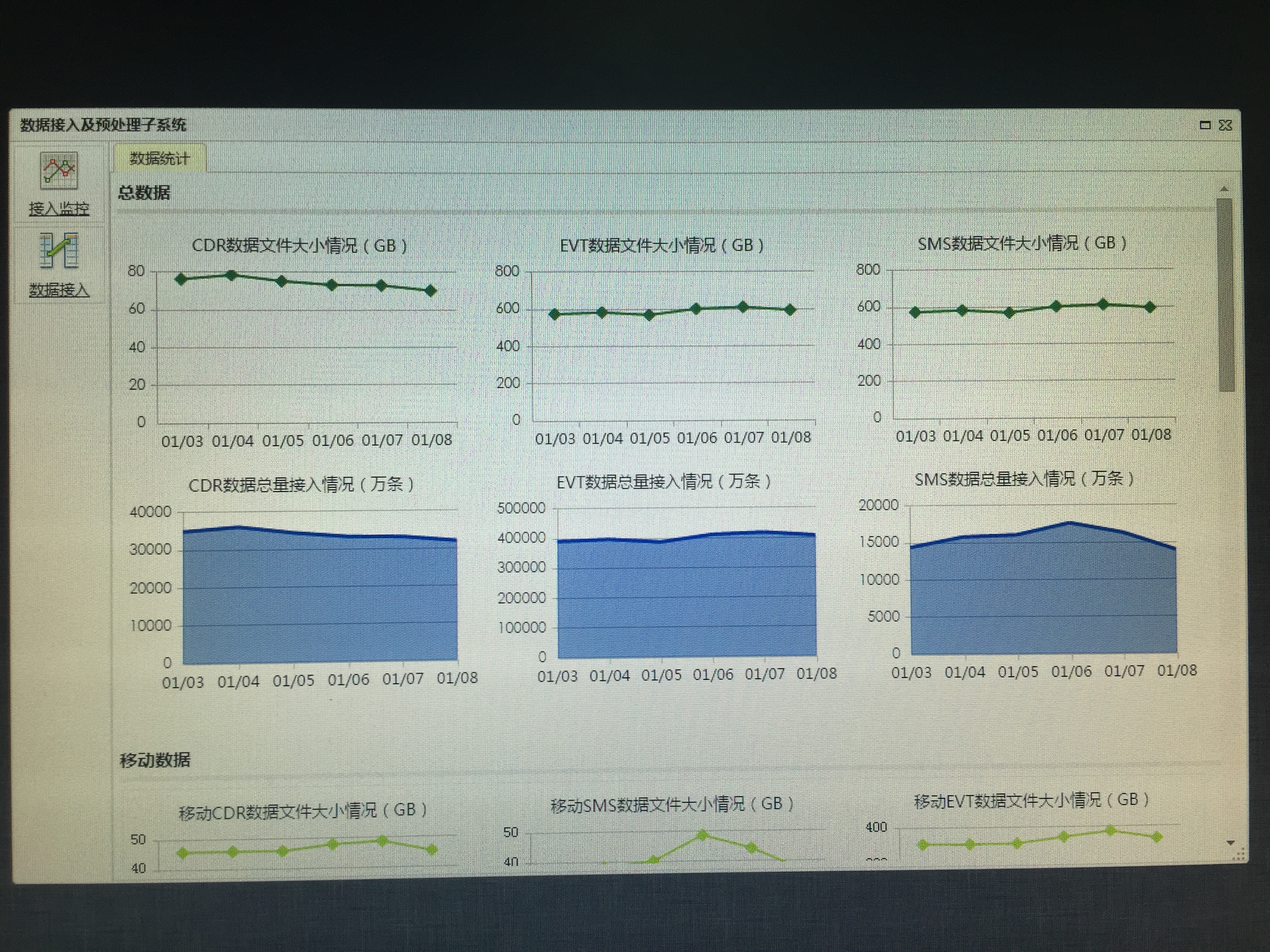
- Data Ingestion:Implemented access and data preprocessing for major business data including Hunan Mobile calls, SMS, events, etc; At present, the total number of platform access has reached trillions; The average daily access data is 3-7T/day, with a total of 13 billion records per day; The largest single item data reached 10 billion pieces per day (mobile event data).
- Processing performance:The main resource library queries, association analysis, activity trajectory analysis, and other business data queries and analysis performance have all reached a response level of seconds, with some business queries reaching a sub second level.
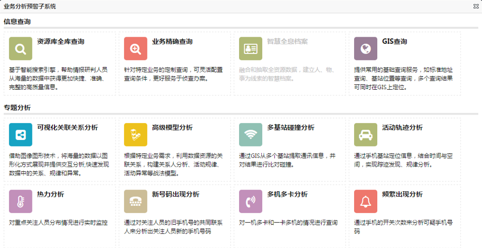
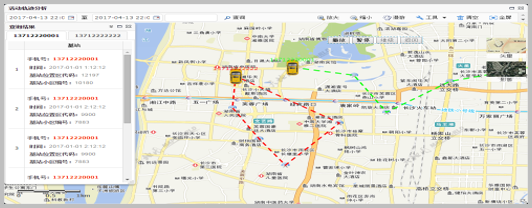
- System functions and business models:Completed the construction of major business function subsystems such as "Data Access and Preprocessing", "Data Center Management", "Business Analysis and Early Warning", "Cluster Management", and "System Management Center". We have implemented business models and functions such as "Resource Database Query", "Precise Business Query", "GIS Query", "Visual Association Analysis", "Advanced Model Analysis", "Multi site Collision Analysis", and "Activity Trajectory Analysis".
2. System Maion Functions
This mainly includes data access and preprocessing subsystems, data center management subsystems, business analysis and early warning subsystems, data backup subsystems, cluster management subsystems, etc.
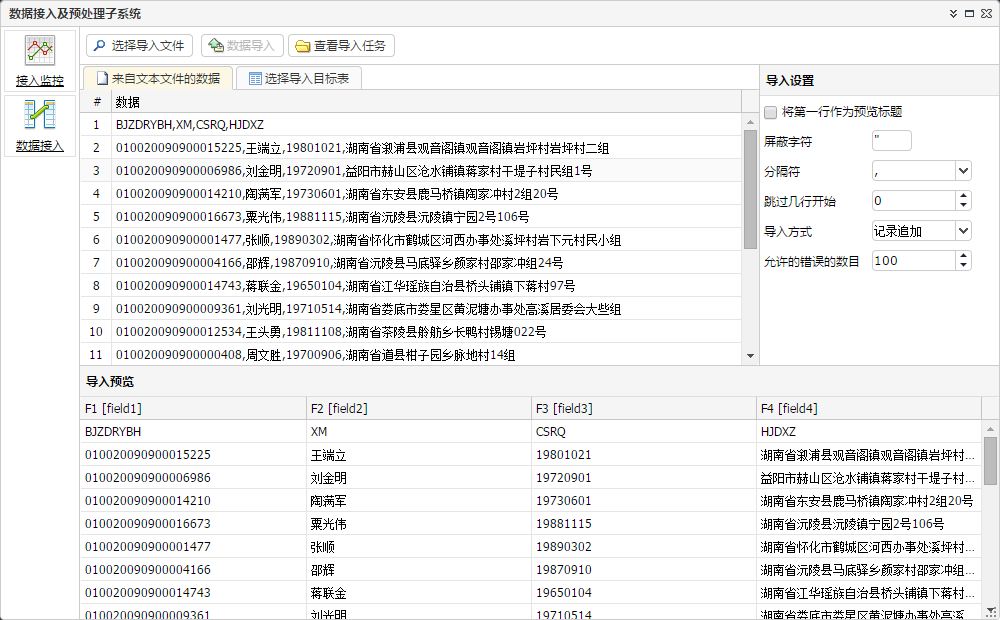
2.1 Data Ingestion and preprocessing subsystem
Used to receive telecommunications business data from the front-end system, and complete further ETL processing such as data extraction, parsing, classification, labeling (according to number type, direction, area identification, behavioral characteristics, etc.). The processed data is stored in the Hadoop/Park cluster to support subsequent business analysis functions, and provided to other back-end systems for use.

2.2 Data Center Management Subsystem
Implement centralized data storage and management functions for the backend big data analysis system. A hybrid architecture based on Hadoop/Spark distributed data processing system and Oracle relational data is used to store, manage, and analyze massive amounts of data to be analyzed and some business target data. Fully integrate the advanced analysis and data mining functions built into the Hadoop system and Oracle database, as well as the distributed computing technologies such as streaming data processing, machine learning, and graphical analysis of the Hadoop open-source framework to support various business analysis and warning functions based on big data.

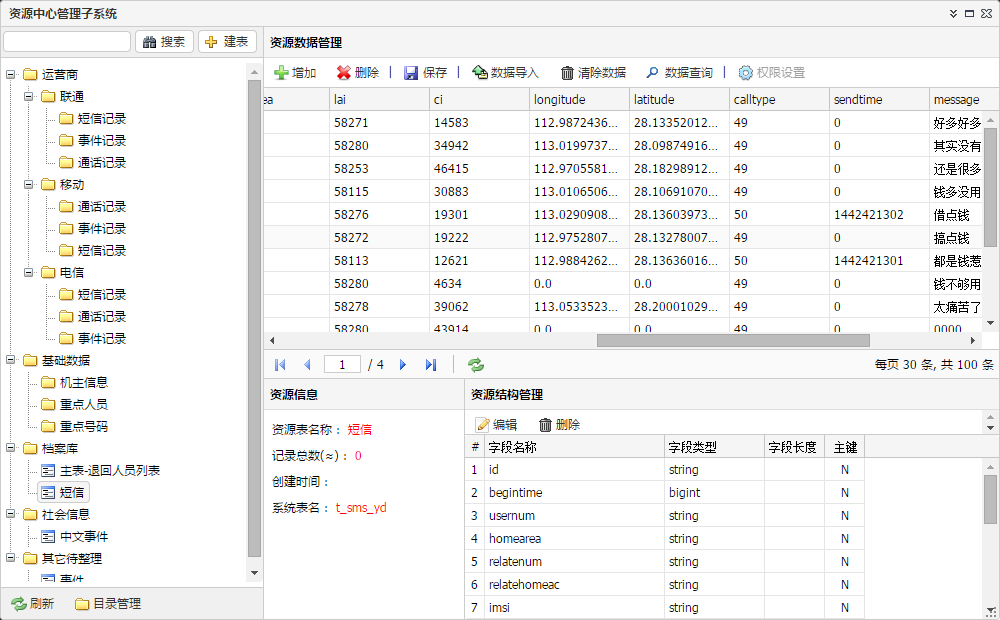
2.3 Business Analysis and Early Warning Subsystem
Based on massive telecommunications data in the background, it supports basic data queries and advanced business analysis needs of business departments.
Data Query: Provides basic data query functionality for all data resource catalogs based on data center management.
Advanced statistical analysis: Provides analysis of business statistical patterns based on massive amounts of data to be analyzed, such as new numbers, multiple machines and cards, frequent connections, etc.
Warning analysis: Automatic warning analysis based on predetermined conditions, such as identifying numbers and crowds that meet behavioral characteristics.
Trend analysis: Analysis of unknown patterns based on intelligent algorithms such as data mining, such as hotspot distribution and crowd aggregation.
Location based graphical analysis and display: Based on the number and location related information contained in telecommunications data, achieve geographical location related number/crowd distribution, geographic fence, and association relationship display.

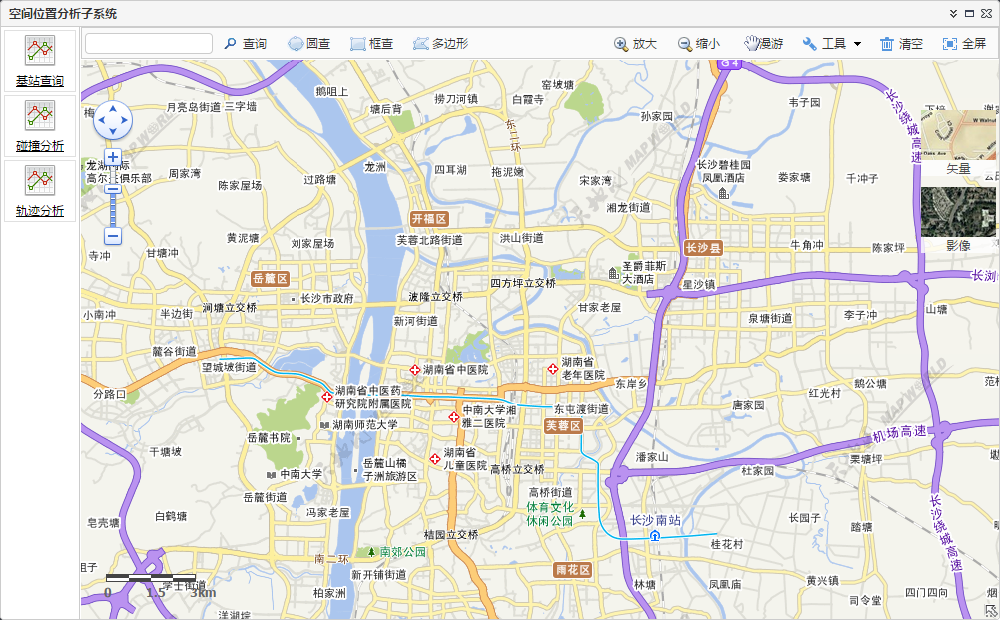
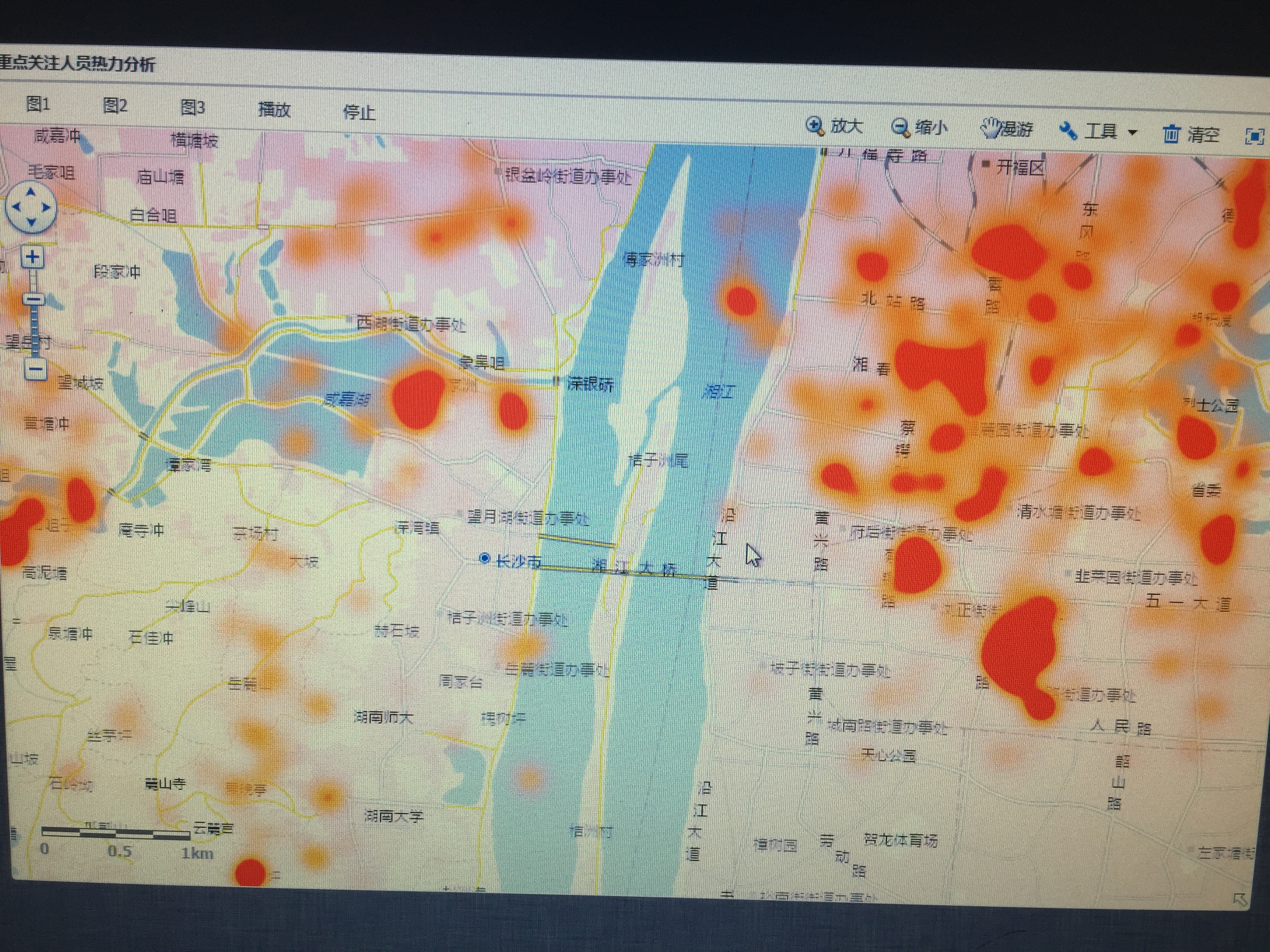
2.4 Data Storage Subsystem
Realize the storage of data obtained throughout the province, backup, restore, archive, and manage the entire business data lifecycle of the backend big data analysis system. The backup system needs to store all detailed and historical data to meet future analysis business expansion needs and data security standards.
2.5 Cluster Management Subsystem
Implement unified management and monitoring of all database nodes and Hadoop cluster nodes of the backend big data analysis system, including node status, storage status, task statistics, etc., and present them to users in a graphical manner.
3. System Architecture Design
The design of the 4G data backend system scheme should fully consider the following business and technical elements:
-High scalability: Supports storing 1-2 years of telecommunications full service data (after data preprocessing), and supports flexible expansion of future storage space and business analysis capabilities.
-High availability: In the event that some cluster nodes fail due to software and hardware issues, the integrity of data and the normal operation of business analysis functions can still be guaranteed.
-Progressiveness of technology: In terms of technical architecture, the advanced/mainstream big data storage and analysis technology and cloud computing technology at home and abroad are selected to ensure the platform's technology leadership in the coming years.
-Business analysis integration: Fully integrate the data and functions of existing systems, provide comprehensive integration of "one click" business analysis functions, and facilitate the use of business analysts.
-Utilize existing resources: Try to utilize existing hardware resources (including storage arrays, servers, etc.) in system design to improve resource utilization.
The overall technical architecture design of the backend big data analysis system can be seen in the following figure:

The system design fully considers the data interaction and functional integration between the big data analysis system and the original front-end and back-end systems, and strives to use the available storage and computing resources of the original system (including storage arrays and existing servers) as much as possible, while meeting the requirements of long-term storage of new full business data (preprocessed) and new business analysis functions (advanced statistics, warning analysis, trend analysis, geographic location based graphical display and analysis).
1) The "data preprocessing subsystem" in the backend big data analysis system directly copies and extracts the telecommunications business source data (compressed text file format) from the shared storage of the front-end system, and uses the ETL server for data preprocessing and processing, mainly including the following processing:
-Data field filtering: Filter out a large number of unnecessary field items in the original data file
-Perform data cleaning and deduplication on duplicate data (determined based on specific business needs)
-Based on the needs of subsequent business analysis, data classification (according to number type, direction, regional identification, behavioral characteristics, etc.), labeling, and statistical summary are processed
The specific technical implementation methods can consider the following:
-Using the Oracle database SQL Loader tool to directly extract source text files for data field filtering and data loading, and using stored procedures and other database class conversions to complete subsequent data classification and other data processing. Its advantage lies in the utilization of existing platform technologies for data loading and conversion, which is convenient to use and has good performance.
-Using Hadoop clusters for data loading, filtering, transformation, classification, and other operations; Using Hive/Spark for massive data ETL process based on HDFS has strong data processing scale and distributed processing capability.
2) After data preprocessing, the business data enters the backend big data analysis system.
The analysis system adopts the mainstream distributed processing system Hadoop/Spark for large-scale data storage and subsequent business computing analysis. The data storage of the Hadoop cluster system can prioritize the use of available disk space in the existing backend system storage array. If there is insufficient storage space in the future, data storage can be carried out through the local hard disk space of newly added Hadoop computing nodes.
Hadoop/Park is a distributed big data storage and computing framework that allows users to develop distributed programs without understanding the underlying details of distribution, fully utilizing cluster capabilities for massive storage and high-performance distributed computing. Hadoop implements a distributed file system called HDFS (Hadoop Distributed File System), which has high fault tolerance. Data is automatically allocated to multiple nodes for redundancy and is designed to be deployed on inexpensive hardware. The Hadoop/Park system supports distributed parallel access to application data, making it suitable for analytical applications with large datasets that require large-scale distributed computing. The main characteristics of the Hadoop/Park system are as follows:
-Strong Scalability: Secure and reliable storage and processing of massive amounts of data ranging from TB to PB, and easy cluster expansion according to business needs.
-Low cost (Economic): Data can be stored and processed through a cluster of ordinary PC servers (using local storage from the server instead of shared disk arrays), with a server cluster size of thousands of nodes
-High Efficient: By distributing computing tasks to different data nodes, Hadoop can parallelly process data on the same node, making business computing processing very fast.
-Reliable: The Hadoop/Park system can automatically maintain multiple copies of data (default is 3 copies), and can automatically redeploy computing tasks after task failures.
By utilizing the excellent scalability of Hadoop/Park architecture (using inexpensive PC server clusters to achieve storage capacities of hundreds to tens of PB), and utilizing Hadoop's distributed computing framework MapReduce/Park technology to implement various new business analysis functions based on Massive Big Data Storage (HDFS), it can solve the scalability and cost limitations of the original disk array+multiple independent Oracle database architectures (original backend systems) when facing future larger data needs.
The technical and business advantages of a backend big data analysis system using Hadoop/Park technology architecture are as follows:
-The scalability of Hadoop/Park clusters based on x86 servers is far superior to traditional disk arrays. Currently, commercial Hadoop clusters can reach thousands of data nodes and store hundreds of PB of data.
-Hadoop/Park clusters have a significant advantage in hardware prices, with hardware costs of less than 30% of disk arrays for the same storage capacity (such as 50T).
-The big data analysis system based on Hadoop/Spark architecture not only provides reliable high-capacity storage, but also supports high-performance computing based on the MapReduce/Park distributed computing framework, which can support various new types of big data business analysis needs in the future (such as advanced statistics, early warning analysis, location-based analysis, etc.).
-The big data analysis system based on Hadoop/Park architecture can provide convenient data access interfaces (using Hive, Oracle Big Data SQL, and other SQL on Hadoop technologies), facilitating data interaction and functional integration between the big data analysis system and other platforms and business systems.
3) After data preprocessing, the business data is not only loaded into the backend big data analysis system, but also enters the data backup system for long-term archiving and storage. These archiving and backup data can be extracted in real-time to the online system for various historical data queries and business analysis as needed. The specific technical implementation methods can be considered as follows:
-Using traditional tape libraries for archiving and backup is cost-effective, but when analyzing archived data, it is necessary to reload the data into an online Hadoop cluster.
-By using a backup Hadoop cluster to store backup data, this backup cluster system and online analysis cluster system can form an Active/Standby mode. Under normal business conditions, the backup cluster is in a standby state. If there is a failure in the online cluster or historical data query and analysis is required, the calculation task can be completed when the backup cluster enters an active state. Its advantage lies in improving the high availability of the entire system (the backup system is also used as a disaster recovery system), but the overall software and hardware costs are relatively high.
4) The data preprocessing subsystem provides the extracted and converted data to the original backend system according to the data format requirements of the backend system (841 system) to support the original query and analysis functions of the existing business system.
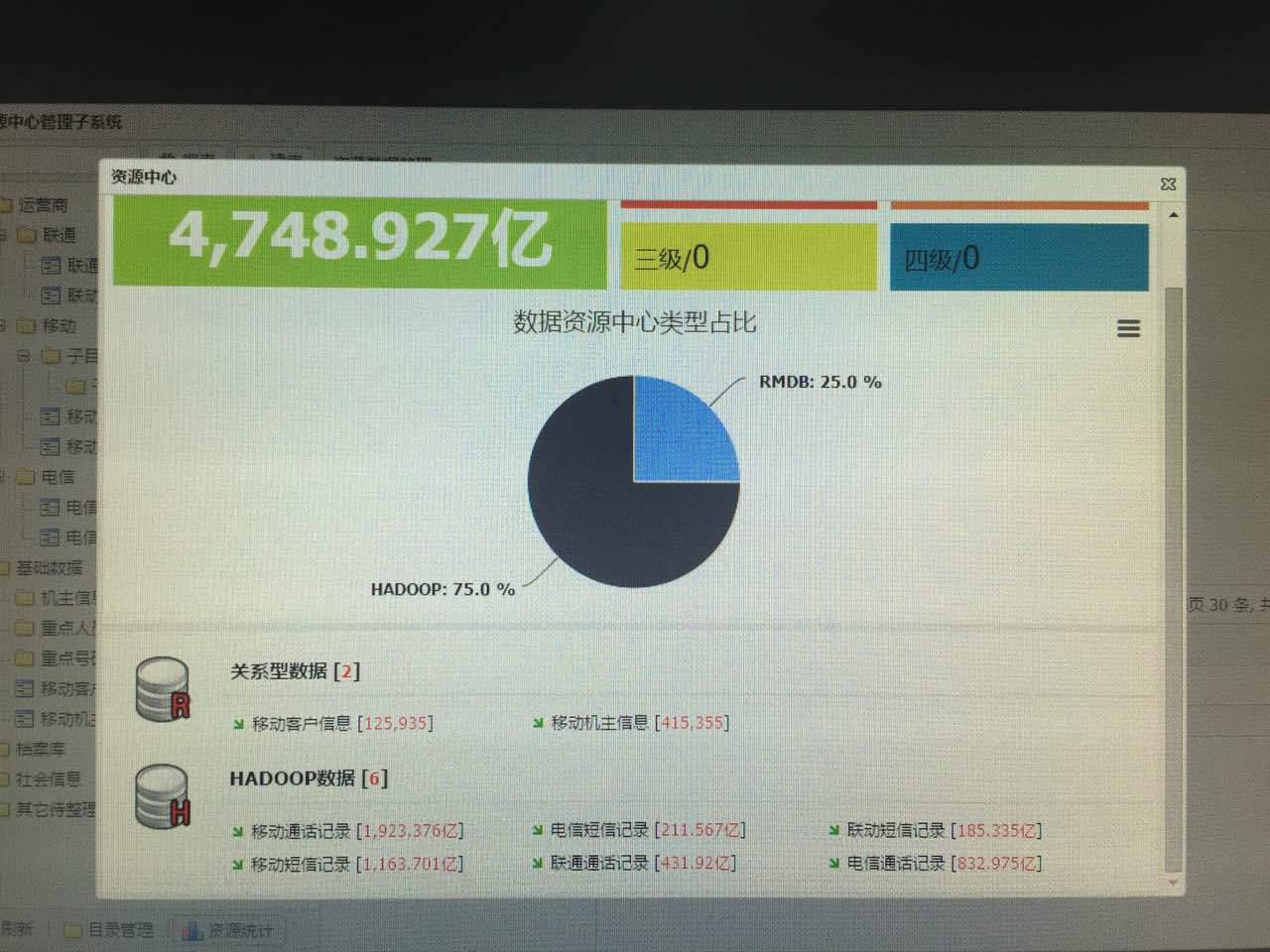
5) The "Data Center Management System" completes the data resource directory management and business data maintenance of the entire backend big data analysis system, which includes the following two parts of data content:
-Data to be analyzed: including various telecommunications business data processed by the "data preprocessing subsystem" and entering the system. This part of the data has a large scale and mainly serves subsequent business analysis functions. Technically, it is stored and analyzed through Hadoop clusters.
-Business core data: including target data, basic data, etc. frequently used by business departments. This part of the data has a large scale, but needs to support daily modification and maintenance work according to the different permissions of business personnel. Technically, it is stored and managed through relational databases.
StarNET© Technology Co., Ltd
913, Building B, Ruichuang International Center, No. 8 Wangjing East Road, Beijing +86 10 68876296
info@starnet-data.com
Website:www.starnet-data.com
WeChat No: starnet-2013